Our Solution
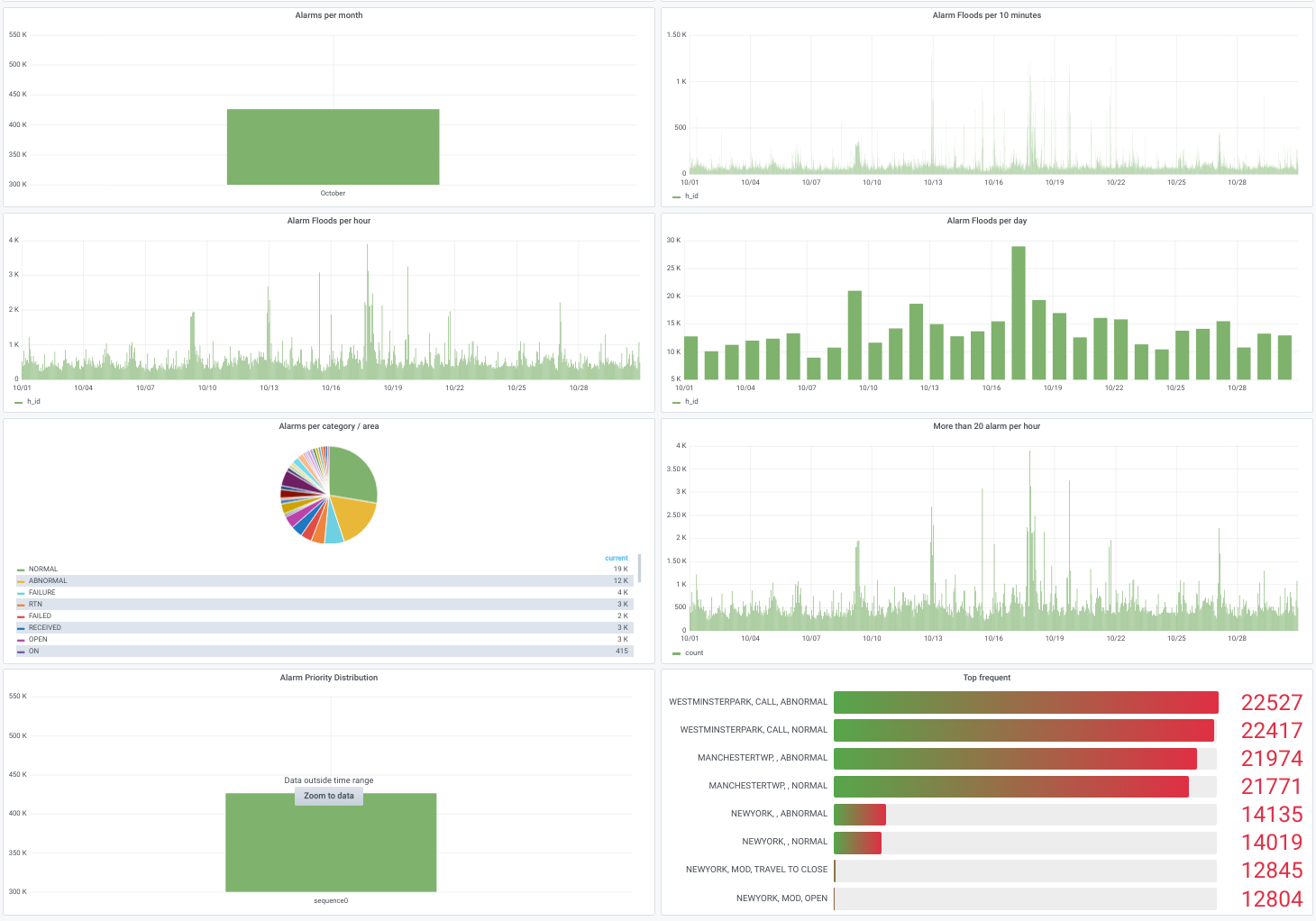
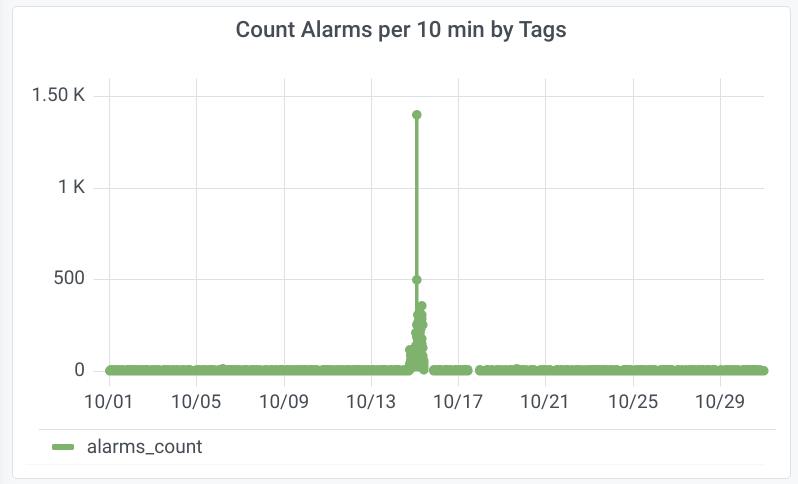
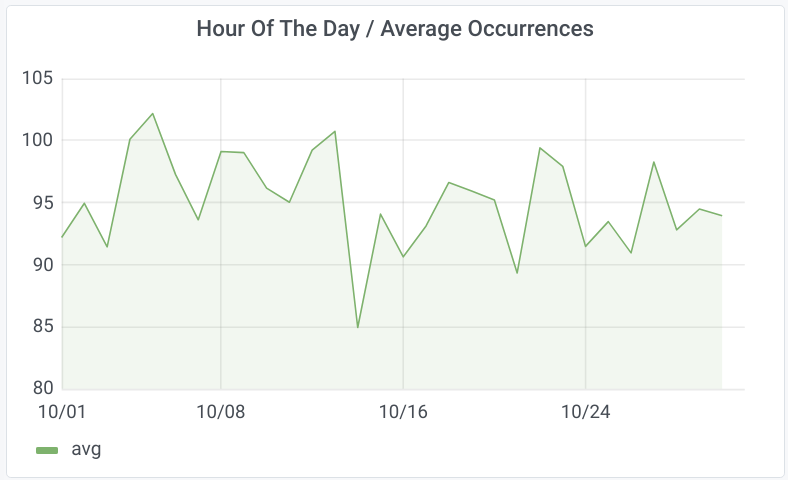
Our solution was tailored to address the client's need for predicting electrical grid faults effectively. We developed a sophisticated data management and analysis system that leveraged a distributed architecture and advanced AI algorithms. Using Dagster for pipeline orchestration, we orchestrated the flow of data seamlessly, enabling efficient analysis. Custom Jupyter scripts facilitated real-time analysis of incoming data streams, providing timely insights into grid performance. Additionally, we implemented Grafana for automated report generation, enabling stakeholders to visualize and understand grid behavior effortlessly. By combining these technologies, we provided the client with a comprehensive solution focused on predicting potential issues and enhancing grid reliability.